Visualisation de vos données automate avec Grafana et InfluxDB
- Par automationsense
- Le 19/06/2020
- Dans Automatisme
- 0 commentaire
Dans nos précédents articles,nous vous avions montré comment paramétrer le serveur OPC UA d'un automate Siemens S7-1200 et comment concevoir un client OPC UA avec le stack Node-OPCUA,dans l'article d'aujourd'hui,nous allons aborder la visualisation de vos données automates provenant de vos machines ou installations.
Sauvegarde des données avec InfluxDB
En effet,lorsque vous aurez collecté les données provenant de votre automate grâce au standard de communication OPC UA,vous aurez besoin de les stocker dans une base de données ou de les visualiser via un tableau de bord.Les quantités de données importantes issues de vos différents capteurs pourront être stockées dans une base de données spéciales de type série temporelle ou time series database.Une des bases de données de type série temporelle les plus utilisées est InfluxDB.InfluxDB est un moteur de base données de type série temporelle qui stockent les données de manière horodatée,les données sont sauvegardées dans l'ordre temporel d'arrivée.InfuxDB diffère des bases de données relationnel,c'est une base de données de type NoSQL c'est à dire que les données sont stockées dans la base de manière non structurée.Pour interroger la base de données,InfluxDB fournit le langage appelé InfluxQL qui est très proche du langage SQL.Que ce soit pour sauvegarder des données de capteurs de vibration,de capteurs de température,de capteurs de pression,de capteurs de vitesse,InfluxDB permet la lecture et l'écriture de ces données temporelles.Pour le stockage de données de type série temporelle,une alternative à InfluxDB est Prometheus.Développé avec le langage Go,Prometheus fournit une base de données série temporelle,un serveur web et un moteur de base de données qui peut être intérrogé via un langage spécifique à Prometheus : le PromQL.
Visualisation des données avec Chronograf ou Grafana
Une fois que vous aurez sauvegardé,les données provenant de vos automates,commandes numériques ou PC industriel dans InfluxDB,il sera aussi possible de les monitorer via un tableau de bord dynamique.Comme outil de visualisation InfluxDB fournit en natif l'outil de visualisation Chronograf mais vous pouvez aussi utiliser Grafana qui est un outil de visualisation open source que vous pourrez utiliser comme plugin avec InfluxDB.Grafana est multiplateforme et peut être déployé avec Docker,il dispose d’une API HTTP complète qui permet de l'utiliser en tant que connecteur.
Pour sauvegarder les données automate dans la base de données InfluxDB,vous pouvez utiliser le schéma suivant : connexion et collecte de données via OPC UA et stockage de ces données via des requêtes HTTP.Vu que nous avons déjà vu comment lire les données d'un automate Siemens S7-1200 via OPC UA,il ne nous reste qu'à stocker ces données dans InfluxDB et procéder à la visualisation.
Cette solution peut,suivant les cas être une alternative à un logiciel de Scada ou de supervision,un des avantages majeurs de Grafana est que la supervision peut se faire avec une interface web,ainsi,vous pouvez accéder à l'intégralité de vos données machine simplement depuis votre navigateur web.Grafana prend en charge plusieurs sources de données parmi lesquelles on peut citer : Prometheus,MySQL,PostgreSQL,Elasticsearch etc..
Installation d'InfluxDB sur macOS
Pour ce qui est de notre cas,nous utilisons un mac,la procédure d'installation peut donc différer suivant le système d'exploitation utilisé.Sur macOS,l'installation d'influxDB s'effectue via le gestionnaire de paquet brew.
Pour installer brew,ouvrez votre terminal et tapez la ligne de commande suivante : /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" et rentrez votre mot de passe sur invitation.

Une fois le gestionnaire de paquet brew installé,vous pouvez installer InfluxDB avec la ligne de commande suivante : brew install influxdb cela a comme conséquence de mettre à jour le gestionnaire de paquet brew et d'installer le package InfluxDB.
Une fois le package InfluxDB installé,tapez les deux commandes suivantes afin de compléter l'installation d'InfluxDB :
ln -sfv /usr/local/opt/influxdb/*.plist ~/Library/LaunchAgents
launchctl load ~/Library/LaunchAgents/homebrew.mxcl.influxdb.plist
Par la suite,vous pouvez tester si InfluxDB a été correctement installé en tapant la commande suivante :
curl -sl -I localhost:8086/ping
Si tout se passe bien,vous devrez avoir le message suivant (voir image ci-dessous)

Comment créer une base de données InfluxDB
Après l'installation d'InfluxDB,pour créer une base de donnée,tapez les commandes suivantes :
influx
CREATE DATABASE automateDB
use automateDB
INSERT siemens,variable=temperature,lieu=machine1 value=100
INSERT siemens,variable=temperature,lieu=machine1 value=200
INSERT siemens,variable=temperature,lieu=machine1 value=300
INSERT siemens,variable=temperature,lieu=machine1 value=400
INSERT siemens,variable=temperature,lieu=machine1 value=500
INSERT siemens,variable=pression,lieu=machine2 value=600
INSERT siemens,variable=pression,lieu=machine2 value=700
INSERT siemens,variable=pression,lieu=machine2 value=800
INSERT siemens,variable=pression,lieu=machine2 value=900
INSERT siemens,variable=pression,lieu=machine2 value=1000
Ici,automateDB représente le nom de la base de données InfluxDB,siemens est un measurement (équivalent d'une table) de la base de données automateDB,variable et lieu sont des tags et value est un field.Dans une base de données InfluxDB,les tags sont indexés alors que les filelds ne sont pas indexés mais tous les deux peuvent être utilisés comme conditions pendant les requêtes.
Comment interroger une base de données InfluxDB
Pour interroger une base de données InfluxDB déjà créée,on utilise le langage de requête InfluxQL.
SELECT * FROM "siemens" : ce requête permet d'afficher tous les enregistrements du measurement siemens.

SELECT * FROM "siemens" WHERE "variable"='pression' : cette requête permet d'afficher uniquement les enregistrements dont le tag variable est égale à pression

DROP DATABASE automateDB : cette requête permet de supprimer la base de données automateDB
DROP measurement siemens : cette requête permet de supprimer le measurement siemens
SHOW DATABASES : cette requête permet d'énumérer l'ensemble des bases de données disponibles sur le serveur
SHOW MEASUREMENTS : cette requête permet d'énumérer l'ensemble des measurements disponible dans une base de données
Installation de Grafana sur macOS
L'installation de Grafana sur macOS est relativement simple.Une fois que vous aussi installé le gestionnaire de paquet brew,vous n'avez qu'à taper la ligne de commande suivante : brew install grafana
Par la suite pour démarrer Grafana,tapez la ligne de commande suivante : brew services start grafana
Une fois le service Grafana démarré,vous pouvez la lancer directement en tapant l'adresse URL suivante au niveau de votre navigateur : http://localhost:3000/login

A partir de là,vous allez rentrer votre login et mot de passe (exemple : admin) afin de vous connecter à l'interface utilisateur de Grafana.
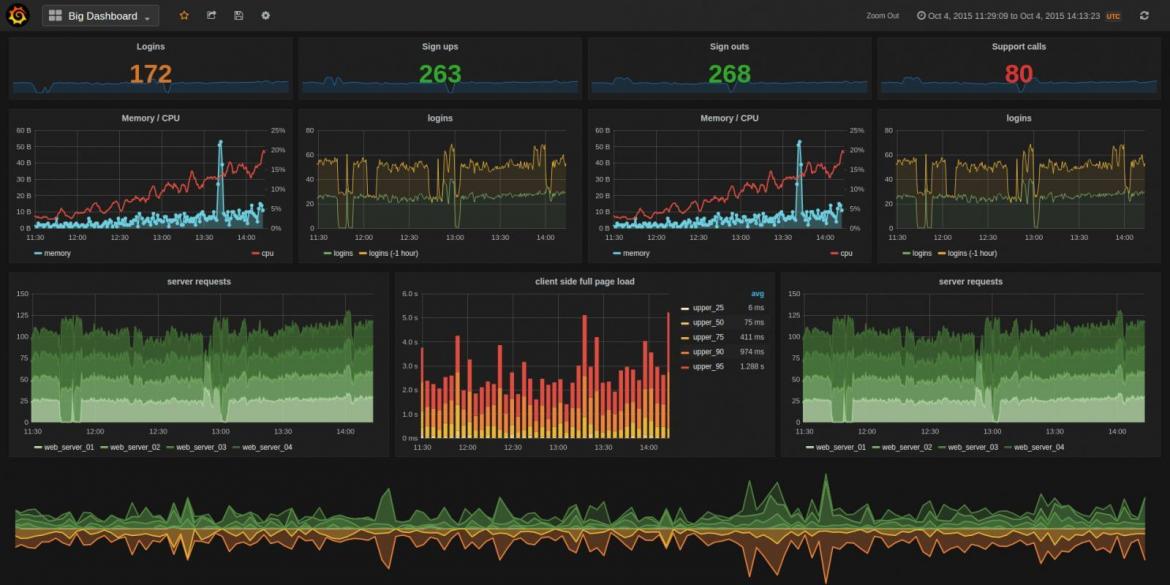
Connexion du client OPC UA avec Grafana
Nous avons développé un client OPC UA qui communique avec notre automate Siemens S7-1200 qui est équipé d'un serveur OPC UA embarqué.Nous avons par la suite connecté notre client OPC UA à InfluxDB de manière à enregistrer en temps réel les données de notre automate S7-1200 dans notre base de données InfluxDB.Par la suite,nous utilisons au niveau de Grafana la source de données InfluxDB qui contient les données de notre automate afin de les monitorer en temps réel (voir image ci-dessous).Il est à signaler que Grafana dispose maintenant d'une source de données OPC,le projet est à ses débuts et est disponible ici.Si vous ne pouvez pas coder votre propre serveur OPC UA,vous pouvez éventuellement utiliser le plugin OPC UA de Grafana.

Utilisation de Telegraf pour la collecte des données automate via le plugin modbus
Dans l'exemple ci-dessus,nous avions développé notre propre serveur de données en Javascript qui permettait d'enregistrer les données de notre automate Siemens S7-1200 dans la base de données InfluxDB,nous allons utiliser pour ce cas ci le module Telegraf pour le datalogging.Telegraf est un module développé en Go qui permet la collecte de metrics à partir de source de données locale ou distante.Telegraf dispose de nombreux plugins comme par exemple des plugins pour se connecter à une base de données Graphite ou Postgresql,pour se connecter à un équipement Modbus,pour se connecter via MQTT etc..Vous pouvez aussi développer votre propre plugin telegraf en langage Go au besoin.
Pour installer telegraf,tapez la ligne de commande suivante : brew install telegraf
Afin d'utiliser telegraf ou un plugin telegraf,vous aurez besoin d'installer Go vu que telegraf a été développé en Go.Vous pouvez installer go sur votre PC en tapant la commande : brew install go
Une fois que go a été installé,tapez les lignes de commande suivantes :
git clone https://github.com/influxdata/telegraf.git
cd telegraf
make
Via les commandes ci-dessous,nous avons téléchargé telegraf depuis github et avons fait un build de la source.Au niveau du répertoire telegraf/telegraf/etc/telegraf.conf se trouve tous les plugins disponibles dans telegraf.C'est aussi au niveau de ce fichier que vous allez paramétrer vos différents plugins.Par exemple,pour paramétrer le plugin modbus,c'est dans ce fichier que vous configurerez l'adresse IP de l'automate ainsi que les différentes variables modbus à monitorer.Ci-dessous quelques paramètres que l'on peut retrouver à propos du plugin modbus de telegraf.
###############################################################################
# INPUT PLUGINS #
###############################################################################
# Retrieve data from MODBUS slave devices
[[inputs.modbus]]
## Connection Configuration
##
## The plugin supports connections to PLCs via MODBUS/TCP or
## via serial line communication in binary (RTU) or readable (ASCII) encoding
##
## Device name
name = "Device"
## Slave ID - addresses a MODBUS device on the bus
## Range: 0 - 255 [0 = broadcast; 248 - 255 = reserved]
slave_id = 1
## Timeout for each request
timeout = "1s"
# TCP - connect via Modbus/TCP
controller = "tcp://192.168.0.1:502"
# Serial (RS485; RS232)
#controller = "file:///dev/ttyUSB0"
#baud_rate = 9600
#data_bits = 8
#parity = "N"
#stop_bits = 1
#transmission_mode = "RTU"
## Measurements
##
## Digital Variables, Discrete Inputs and Coils
## name - the variable name
## address - variable address
## Analog Variables, Input Registers and Holding Registers
## name - the variable name
## byte_order - the ordering of bytes
## |---AB, ABCD - Big Endian
## |---BA, DCBA - Little Endian
## |---BADC - Mid-Big Endian
## |---CDAB - Mid-Little Endian
## data_type - UINT16, INT16, INT32, UINT32, FLOAT32, FLOAT32-IEEE (the IEEE 754 binary representation)
## scale - the final numeric variable representation
## address - variable address
holding_registers = [
{ name = "temperature", byte_order = "AB", data_type = "INT16", scale=1.0, address = [1]},
]
Dans les paramètres du plugin telegraf ci-dessus,nous avons renseigné l'adresse IP de notre automate S7-1200,puis choisit le mode de communication via modbus TCP/IP.Nous avons utiliser le bloc MB_Server au niveau de TIA Portal.Ne pas oublier de décocher l'accès au bloc optimé dans les paramètres du bloc DB contenant les holding register à lire.Pour les données du holding register,c'est un tableau de dimension 2 contenant 2 INT.Le premier INT dont l'emplacement est 0.0 a comme valeur 187 et le deuxième INT dont l'emplacement est 2.0 a comme valeur 189.

Une fois que vous aurez configuré le plugin telegraf modbus,vous pouvez taper la commande telegraf --help afin d'avoir une aide sur les différents arguments de telegraf (notamment les arguments --config , --test et --sample-config).
Par la suite tapez les commandes suivantes au niveau de votre terminal (depuis le répertoire /telegraf)
telegraf --sample-config --input-filter modbus --output-filter influxdb > testmodbus.conf (données entrantes : modbus , données sortantes : influxDB et sauvegarde configuration finale dans le fichier testmodbus.conf)
telegraf --config testmodbus.conf --test (exécution de telegraf avec les paramètres définis dans le fichier testmodbus.conf)
NB : A chaque fois que vous modifierez le fichier de config (ici testmodbus.conf),vous aurez besoin de redémarrer le service telegraf avec la commande suivante : brew services restart telegraf
Comme on peur le voir sur l'image ci-dessous,nous récupérons bien les variables de notre automate S7-1200 avec notre plugin telegraf,la variable que nous répérons c'est température qui est égale à 189.

Nous contacter
formation automatisme automate programmable
Ajouter un commentaire



































